
YARN
YARN (Yet Another Resource Negotiator)은 하둡 2부터 도입된 클러스터 리소스 관리, 애플리케이션 라이프 사이클 관리를 위한 아키텍처이다. YARN에서는 맵리듀스 기반의 애플리케이션외에도 피그, 스톰, 스파크 등 분산 애플리케이션에 대해 클러스터 리소스를 관리 할 수 있다.
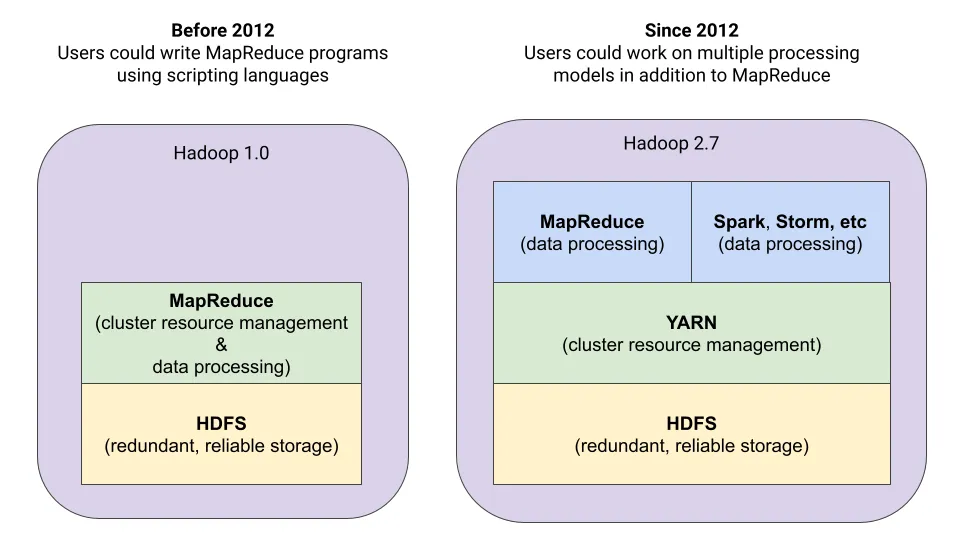
YARN 아키텍처의 세 가지 중요한 요소는 리소스 매니저, 노드 매니저, 애플리케이션 마스터이다.
리소스 매니저
리소스 매니저(Resource Manager)는 하둡 클러스터의 마스터 노드에 실행되는 자바 프로세서로 노드 매니저로부터 전달받은 정보를 이용하여 클러스터에서 CPU, 메모리, 디스크 등의 자원을 관리한다.
- 클러스터 상태 모니터링 : 클러스터 내 노드의 상태를 모니터링하고 노드 장애 발생 시 리소스 장애 조치 수행
- 클러스터 자원 할당 : 애플리케이션 마스터로부터 자원 요청을 받아 애플리케이션 실행에 필요한 자원 할당
리소스 매니저는 애플리케이션 마스터의 요청을 받아 자원을 할당하는데 이때 자원 할당을 위한 정책을 스케줄러라고 한다. FIFO, Fair, Capacity 스케줄러 등이 있으며 하둡 2의 기본 스케줄러는 Capacity 스케줄러이다. 스케줄러는 yarn-site.xml에서 설정할 수 있다.
노드 매니저
노드 매니저(Node Manager)는 클러스터의 각 슬레이브(워커) 노드에서 실행되는 자바 프로세서로, 현재 노드의 자원 상태를 관리하고 리소스 매니저에 현재 자원 상태를 보고한다.
- 노드 상태 보고 : 각 노드 매니저는 리소스 매니저에게 주기적으로 하트 비트를 보내 메모리 및 가상 코어를 포함한 노드 상태와 정보를 제공. 만약 노드에 장애가 발생하면 리소스 매니저에게 문제 보고
- 컨테이너 시작 : 노드 매니저는 리소스 매니저의 지시를 받아 지정된 자원의 제약조건으로 컨테이너를 구축
- 컨테이너 관리 : 노드 매니저는 컨테이너 라이프 사이클, 종속성, 리소스 사용량, 로그, 리스(leases)를 관리
애플리케이션 마스터
애플리케이션 마스터(Application Master)는 Spark 드라이버 프로그램와 같은 애플리케이션 메인 함수를 실행하는 프로세스이다.
- 리소스 요청 : 컨테이너를 시작하기 위해, 리소스 매니저에게 자원 요청
- 애플리케이션 실행 : 애플리케이션을 분산 처리 클러스터에서 실행
컨테이너
컨테이너는 클러스터의 워커 노드를 나타내는 추상화된 리소스 할당 단위이다. 컨테이너에서 MapReduce 작업 또는 Spark 작업와 같은 애플리케이션 작업을 실행한다. 각 컨테이너에는 CPU, 메모리, 디스크 공간 등의 리소스가 할당되어 있으며 컨테이너마다 격리된 환경에서 작업을 실행한다.
YARN에서 애플리케이션이 실행되는 방식
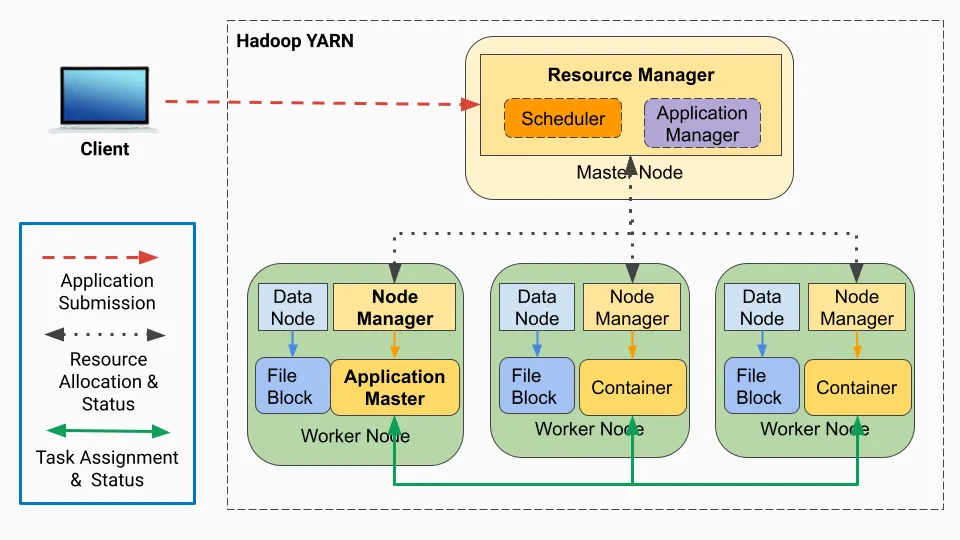
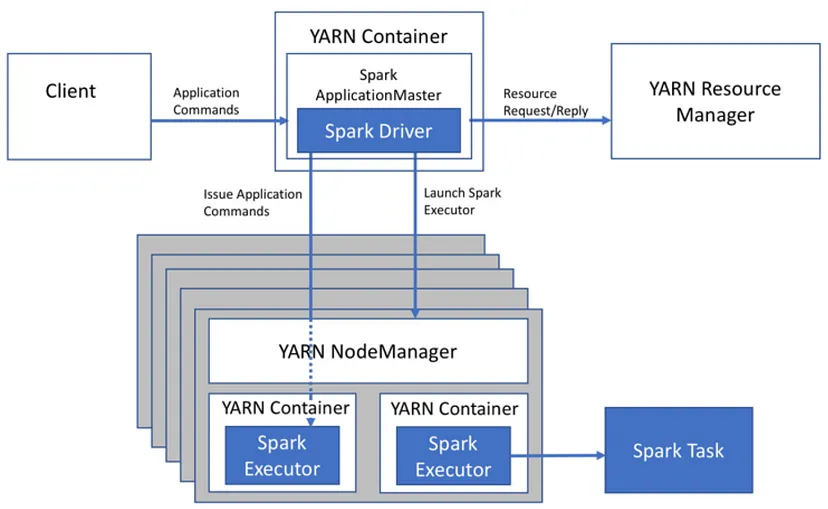
아래는 YARN에서 Spark 애플리케이션을 실행할 때, 처리 과정을 나타낸 그림이다.
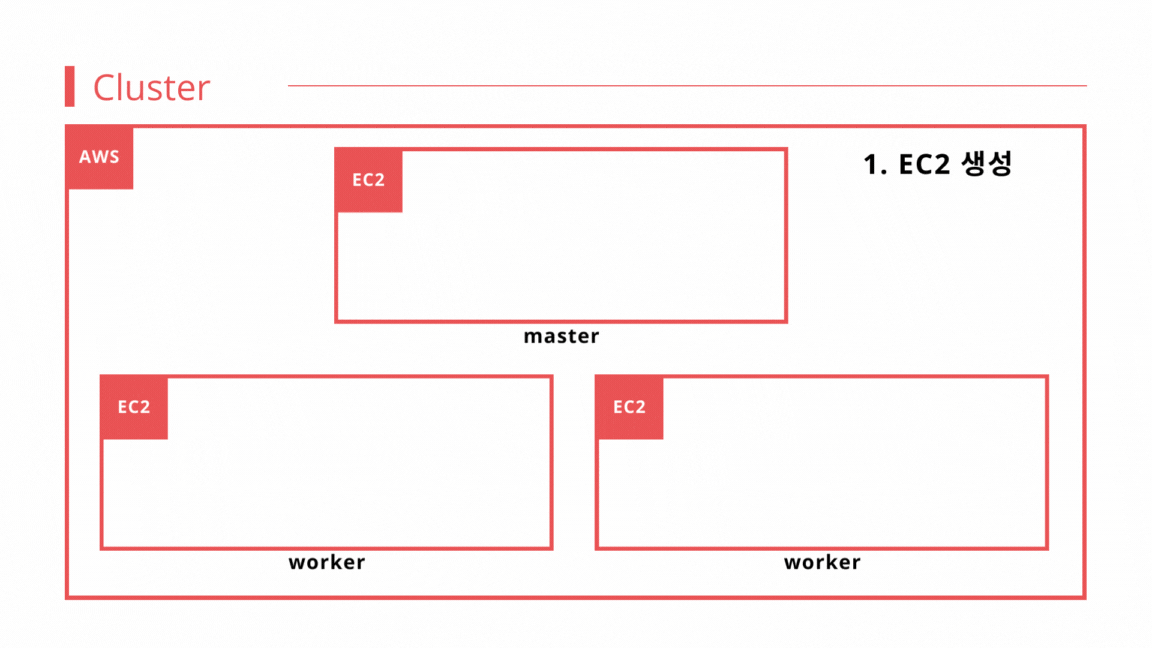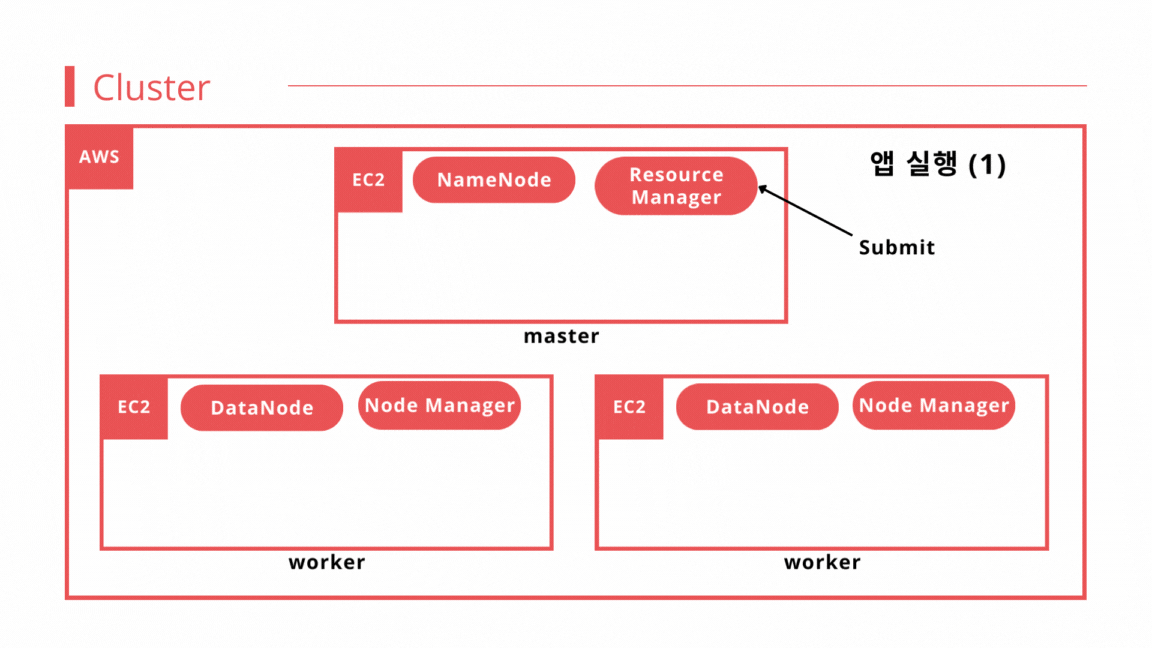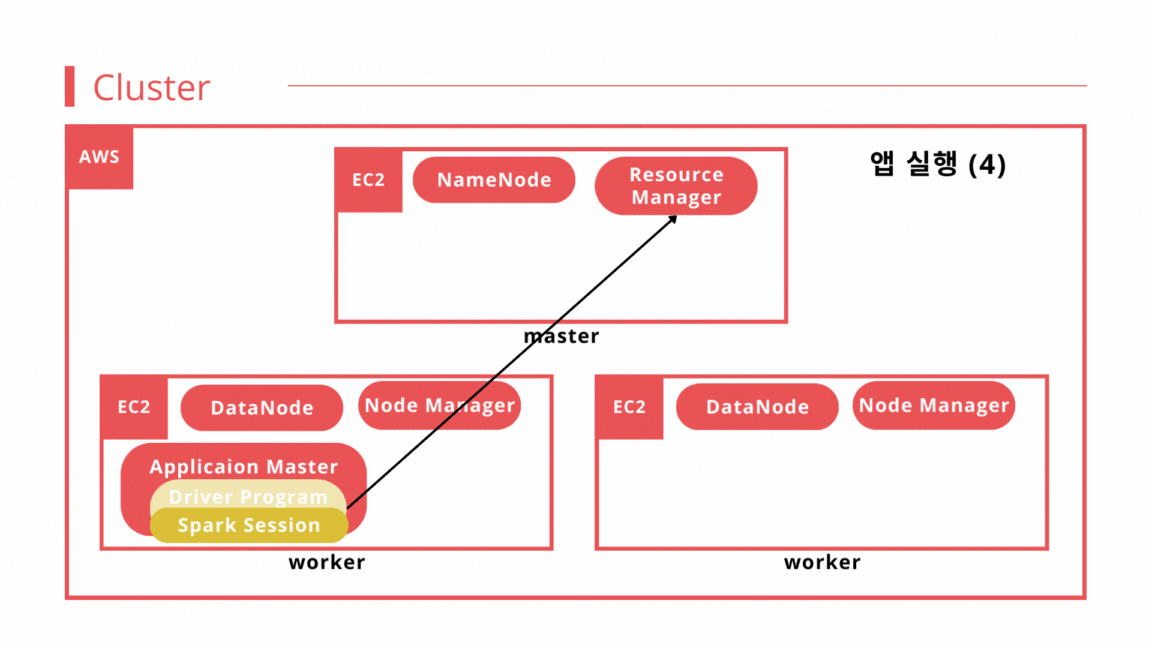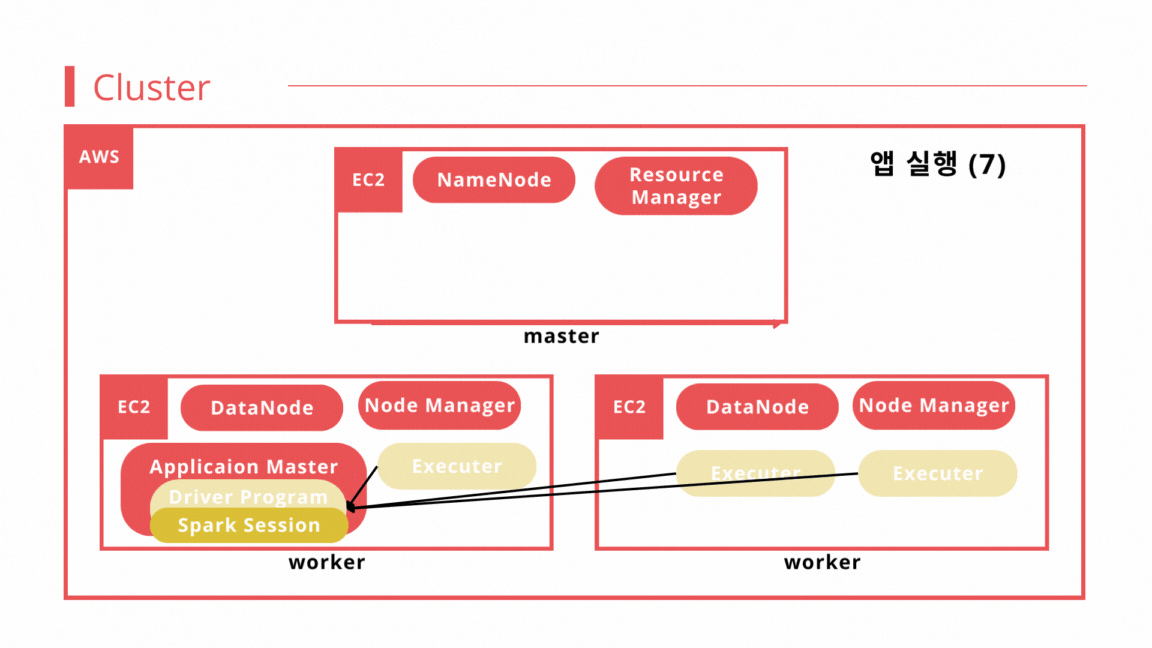
- 앱 실행 1 : 클라이언트는 spark-submit을 사용해 YARN 리소스 매니저에게 job을 제출한다. 제출된 job은 리소스 매니저의 스케줄러 대기열에 들어가 실행 되기를 기다린다.
- 앱 실행 2 : job이 실행될 때가 되면 리소스 매니저는 컨테이너를 실행할 수 있는 노드 매니저를 찾고 애플리케이션 마스터(컨테이너)를 할당한다.
- 앱 실행 3 : 애플리케이션 마스터는 드라이버 프로그램을 실행한다.
- 앱 실행 4 : 애플리케이션 마스터는 작업에 필요한 리소스를 계산하고, 리소스 매니저에게 이그제큐터를 시작하도록 요청한다.
- 앱 실행 5 : 리소스 매니저는 요청받은 리소스에 맞춰 워커 노드에 이그제큐터 컨테이너를 할당한다.
- 앱 실행 6 : 드라이버 프로그램은 이그제큐터 컨테이너에 task를 할당하고 task 상태를 추적한다.
- 앱 실행 7 : 이그제큐터 컨테이너는 task를 실행하고 결과를 드라이버 프로그램으로 리턴한다. 드라이버 프로그램은 결과를 집계하여 최종 출력을 생성한다.
YARN 메모리 설정
YARN 메모리 설정은 yarn-site 파일을 수정하여 변경할 수 있다. 노드매니저의 메모리, CPU 개수와 컨테이너에 할당할 수 있는 최대, 최소 메모리 등을 설정할 수 있다. 기본 값은 yarn-default.xml 파일을 확인하면 된다.
yarn.nodemanager.resource.memory-mb
- 클러스터의 각 노드에서 컨테이너 운영에 설정할 수 있는 메모리의 총량
- 노드의 OS를 운영할 메모리를 제외하고 설정
- 기본값은 장비에 설정된 메모리의 80%
yarn.nodemanager.resource.cpu-vcores
- 클러스터 각 노드에서 컨테이너 운영에 설정할 수 있는 CPU 코어 개수
- 기본값은 장비에 설치된 CPU 코어의 80%
yarn.scheduler.maximum-allocation-mb
- 하나의 컨테이너에 할당할 수 있는 메모리 최대 값
- 8G가 기본 값
yarn.scheduler.minimum-allocation-mb
- 하나의 컨테이너에 할당할 수 있는 메모리 최소 값
- 1G가 기본 값
yarn.nodemanager.vmem-pmem-ratio
- 실제 메모리 대비 가상 메모리 사용 비율
- mapreduce.map.memory.mb * 설정값의 비율로 사용 가능
- 메모리를 1G로 설정하고, 이 값을 10으로 설정하면 가상메모리를 10G 사용
yarn.nodemanager.vmem-check-enabled
- 가상 메모리에 대한 제한이 있는지 확인하여, true 일 경우 메모리 사용량을 넘어서면 컨테이너를 종료
yarn.nodemanager.pmem-check-enabled
- 물리 메모리에 대한 제한이 있는지 확인하여, true 일 경우 메모리 사용량을 넘어서면 컨테이너를 종료
참고
Demystifying YARN: Understanding Its Architecture, Components, and How It Works
An In-Depth Guide to Hadoop YARN: Resource Management and Task Scheduling for Large-Scale Distributed Systems
medium.com
https://eyeballs.tistory.com/82
[Spark] YARN 위에서 Application 을 실행하는 단계
스파크 어플리케이션이 YARN에서 실행되면 먼저 어플리케이션 마스터(Application Master) 프로세스가 생성이 되는 데 이것이 바로 Spark Driver를 실행하는 컨테이너가 됩니다. 그리고 이 Spark Driver가 YARN
eyeballs.tistory.com
'Hadoop Echo System' 카테고리의 다른 글
| 스파크 애플리케이션 제출 (0) | 2024.03.04 |
|---|---|
| 스파크 클러스터 (0) | 2024.03.03 |
YARN
YARN (Yet Another Resource Negotiator)은 하둡 2부터 도입된 클러스터 리소스 관리, 애플리케이션 라이프 사이클 관리를 위한 아키텍처이다. YARN에서는 맵리듀스 기반의 애플리케이션외에도 피그, 스톰, 스파크 등 분산 애플리케이션에 대해 클러스터 리소스를 관리 할 수 있다.
YARN 아키텍처의 세 가지 중요한 요소는 리소스 매니저, 노드 매니저, 애플리케이션 마스터이다.
리소스 매니저
리소스 매니저(Resource Manager)는 하둡 클러스터의 마스터 노드에 실행되는 자바 프로세서로 노드 매니저로부터 전달받은 정보를 이용하여 클러스터에서 CPU, 메모리, 디스크 등의 자원을 관리한다.
- 클러스터 상태 모니터링 : 클러스터 내 노드의 상태를 모니터링하고 노드 장애 발생 시 리소스 장애 조치 수행
- 클러스터 자원 할당 : 애플리케이션 마스터로부터 자원 요청을 받아 애플리케이션 실행에 필요한 자원 할당
리소스 매니저는 애플리케이션 마스터의 요청을 받아 자원을 할당하는데 이때 자원 할당을 위한 정책을 스케줄러라고 한다. FIFO, Fair, Capacity 스케줄러 등이 있으며 하둡 2의 기본 스케줄러는 Capacity 스케줄러이다. 스케줄러는 yarn-site.xml에서 설정할 수 있다.
노드 매니저
노드 매니저(Node Manager)는 클러스터의 각 슬레이브(워커) 노드에서 실행되는 자바 프로세서로, 현재 노드의 자원 상태를 관리하고 리소스 매니저에 현재 자원 상태를 보고한다.
- 노드 상태 보고 : 각 노드 매니저는 리소스 매니저에게 주기적으로 하트 비트를 보내 메모리 및 가상 코어를 포함한 노드 상태와 정보를 제공. 만약 노드에 장애가 발생하면 리소스 매니저에게 문제 보고
- 컨테이너 시작 : 노드 매니저는 리소스 매니저의 지시를 받아 지정된 자원의 제약조건으로 컨테이너를 구축
- 컨테이너 관리 : 노드 매니저는 컨테이너 라이프 사이클, 종속성, 리소스 사용량, 로그, 리스(leases)를 관리
애플리케이션 마스터
애플리케이션 마스터(Application Master)는 Spark 드라이버 프로그램와 같은 애플리케이션 메인 함수를 실행하는 프로세스이다.
- 리소스 요청 : 컨테이너를 시작하기 위해, 리소스 매니저에게 자원 요청
- 애플리케이션 실행 : 애플리케이션을 분산 처리 클러스터에서 실행
컨테이너
컨테이너는 클러스터의 워커 노드를 나타내는 추상화된 리소스 할당 단위이다. 컨테이너에서 MapReduce 작업 또는 Spark 작업와 같은 애플리케이션 작업을 실행한다. 각 컨테이너에는 CPU, 메모리, 디스크 공간 등의 리소스가 할당되어 있으며 컨테이너마다 격리된 환경에서 작업을 실행한다.
YARN에서 애플리케이션이 실행되는 방식
아래는 YARN에서 Spark 애플리케이션을 실행할 때, 처리 과정을 나타낸 그림이다.
- 앱 실행 1 : 클라이언트는 spark-submit을 사용해 YARN 리소스 매니저에게 job을 제출한다. 제출된 job은 리소스 매니저의 스케줄러 대기열에 들어가 실행 되기를 기다린다.
- 앱 실행 2 : job이 실행될 때가 되면 리소스 매니저는 컨테이너를 실행할 수 있는 노드 매니저를 찾고 애플리케이션 마스터(컨테이너)를 할당한다.
- 앱 실행 3 : 애플리케이션 마스터는 드라이버 프로그램을 실행한다.
- 앱 실행 4 : 애플리케이션 마스터는 작업에 필요한 리소스를 계산하고, 리소스 매니저에게 이그제큐터를 시작하도록 요청한다.
- 앱 실행 5 : 리소스 매니저는 요청받은 리소스에 맞춰 워커 노드에 이그제큐터 컨테이너를 할당한다.
- 앱 실행 6 : 드라이버 프로그램은 이그제큐터 컨테이너에 task를 할당하고 task 상태를 추적한다.
- 앱 실행 7 : 이그제큐터 컨테이너는 task를 실행하고 결과를 드라이버 프로그램으로 리턴한다. 드라이버 프로그램은 결과를 집계하여 최종 출력을 생성한다.
YARN 메모리 설정
YARN 메모리 설정은 yarn-site 파일을 수정하여 변경할 수 있다. 노드매니저의 메모리, CPU 개수와 컨테이너에 할당할 수 있는 최대, 최소 메모리 등을 설정할 수 있다. 기본 값은 yarn-default.xml 파일을 확인하면 된다.
yarn.nodemanager.resource.memory-mb
- 클러스터의 각 노드에서 컨테이너 운영에 설정할 수 있는 메모리의 총량
- 노드의 OS를 운영할 메모리를 제외하고 설정
- 기본값은 장비에 설정된 메모리의 80%
yarn.nodemanager.resource.cpu-vcores
- 클러스터 각 노드에서 컨테이너 운영에 설정할 수 있는 CPU 코어 개수
- 기본값은 장비에 설치된 CPU 코어의 80%
yarn.scheduler.maximum-allocation-mb
- 하나의 컨테이너에 할당할 수 있는 메모리 최대 값
- 8G가 기본 값
yarn.scheduler.minimum-allocation-mb
- 하나의 컨테이너에 할당할 수 있는 메모리 최소 값
- 1G가 기본 값
yarn.nodemanager.vmem-pmem-ratio
- 실제 메모리 대비 가상 메모리 사용 비율
- mapreduce.map.memory.mb * 설정값의 비율로 사용 가능
- 메모리를 1G로 설정하고, 이 값을 10으로 설정하면 가상메모리를 10G 사용
yarn.nodemanager.vmem-check-enabled
- 가상 메모리에 대한 제한이 있는지 확인하여, true 일 경우 메모리 사용량을 넘어서면 컨테이너를 종료
yarn.nodemanager.pmem-check-enabled
- 물리 메모리에 대한 제한이 있는지 확인하여, true 일 경우 메모리 사용량을 넘어서면 컨테이너를 종료
참고
Demystifying YARN: Understanding Its Architecture, Components, and How It Works
An In-Depth Guide to Hadoop YARN: Resource Management and Task Scheduling for Large-Scale Distributed Systems
medium.com
https://eyeballs.tistory.com/82
[Spark] YARN 위에서 Application 을 실행하는 단계
스파크 어플리케이션이 YARN에서 실행되면 먼저 어플리케이션 마스터(Application Master) 프로세스가 생성이 되는 데 이것이 바로 Spark Driver를 실행하는 컨테이너가 됩니다. 그리고 이 Spark Driver가 YARN
eyeballs.tistory.com
'Hadoop Echo System' 카테고리의 다른 글
| 스파크 애플리케이션 제출 (0) | 2024.03.04 |
|---|---|
| 스파크 클러스터 (0) | 2024.03.03 |